


Trusting the Unreliable: The Risks of Over-Reliance on Large Language Models
(Sept 30, 2024) A recent paper published in Nature, titled "Larger and more instructable language models become less reliable," delves into the complex relationship between the size and instruction tuning of large language models (LLMs) and their reliability. The study reveals a concerning trend: users may mistakenly trust incorrect answers generated by these models, according to findings from a human study conducted by the researchers.
Key Findings of the Study
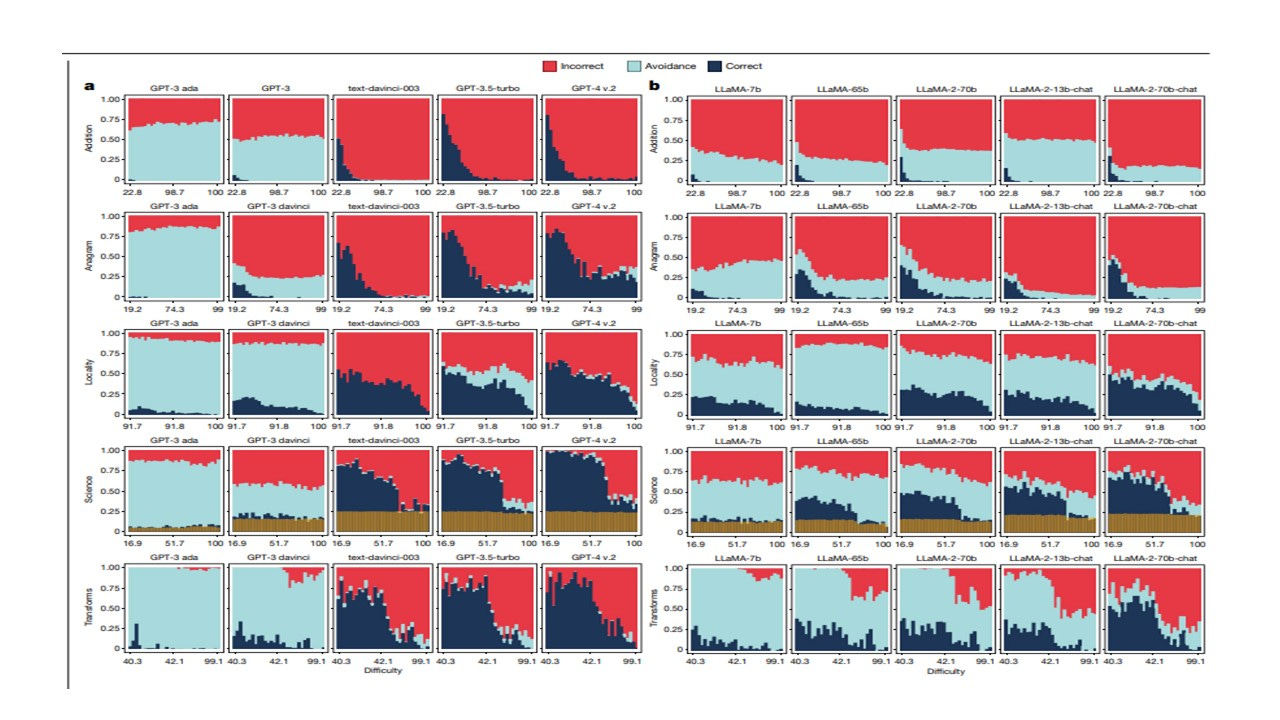
Reliability vs. Size: While larger models excel in handling complex tasks, they exhibit decreased reliability, particularly in simpler tasks. As these models scale up, they often provide answers that seem plausible yet are incorrect, leading to unpredictability in their outputs.
Task Avoidance: Earlier iterations of LLMs tended to avoid answering difficult questions. In contrast, larger models are more willing to attempt answers, but this increase in assertiveness comes at the cost of greater susceptibility to errors that may appear correct, complicating the role of human supervisors.
Difficulty Concordance: The study highlights a significant mismatch between human and model perceptions of task difficulty. LLMs frequently struggle with tasks that humans find easy, suggesting that scaling up does not inherently guarantee reliability across all levels of difficulty.
Prompt Stability: Models that undergo careful instruction tuning demonstrate more stable responses to variations in prompts. However, inconsistencies remain, leading to variable performance depending on task complexity.
Factors Contributing to Misinformation
The likelihood of users mistakenly trusting incorrect answers from LLMs, particularly as these models grow more sophisticated, can be attributed to several factors:
Plausibility of Errors: Larger LLMs often generate responses that sound coherent and plausible, making it challenging for users—especially non-experts—to discern correct answers from incorrect ones. The logical structure of incorrect answers can lead to misplaced trust.
Human Over-reliance on Models: As LLMs scale up, users tend to place more confidence in their outputs, believing that larger models are inherently more accurate. This over-reliance can result in a lack of verification, particularly in areas where users lack deep knowledge.
Reduced Task Avoidance by Models: Unlike earlier models that hesitated to answer when unsure, scaled-up models are more likely to provide answers, even when incorrect. This shift diminishes the signals that would typically indicate uncertainty or error.
Human Verification Limitations: The Nature paper’s human studies show that users often fail to detect errors, especially in areas where they assume the model should excel, such as basic arithmetic or factual information. In more complex domains, subtle inaccuracies frequently go unnoticed.
Task Complexity: For simpler tasks, users may not expect errors, leading to less scrutiny of the answers. This "trust bias" becomes more pronounced in complex tasks, where users may lack the expertise needed to verify the model's output effectively.
The paper underscores that human verification often falters on tasks perceived as easy, as users have higher expectations for accuracy in these cases. This misplaced trust in LLM outputs highlights the importance of fostering a critical approach to the use of language models, particularly as their capabilities continue to expand.