
Microsoft Launches Custom Silicon: The Maia 200 and the New Economics of AI Inference
In a move that signals a deepening “silicon arms race” among cloud hyperscalers, Microsoft has officially unveiled the Maia 200, its second-generation custom AI accelerator. Engineered specifically for the massive inference demands of frontier models like OpenAI’s GPT-5.2, the Maia 200 represents a significant pivot from general-purpose hardware toward specialized, cost-efficient token generation at scale with native FP8/FP4 tensor cores.

The Technical Powerhouse
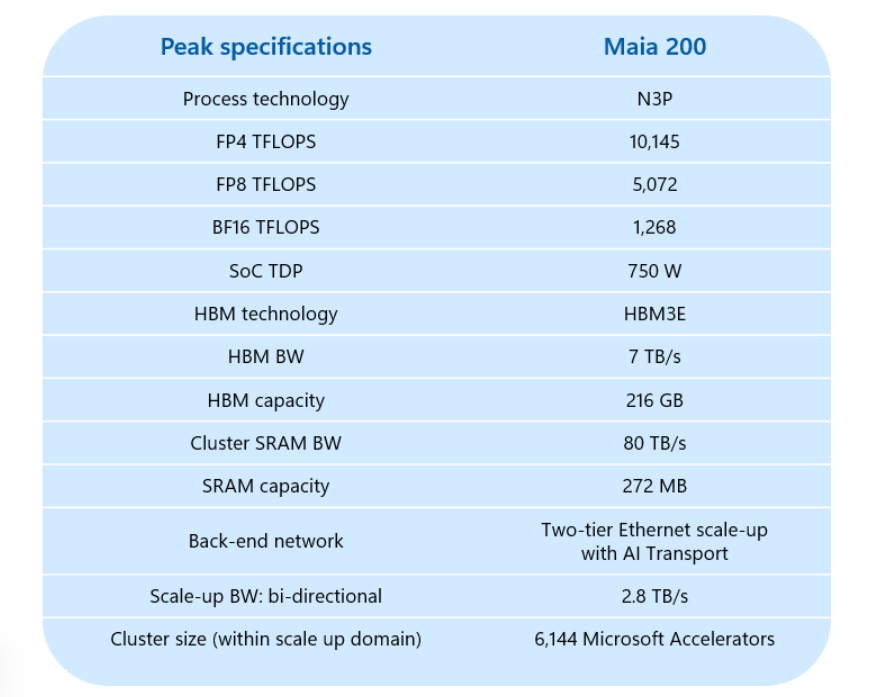
Built on TSMC’s cutting-edge 3nm process, the Maia 200 is designed to bridge the gap between peak performance and operational efficiency. Microsoft reports that the chip delivers over 10 PetaFLOPS of 4-bit (FP4) throughput and approximately 5 PetaFLOPS of 8-bit (FP8) performance.
Key technical specifications include:
Memory Subsystem: 216GB of HBM3e memory providing a massive 7 TB/s of bandwidth.
On-Chip Storage: 272MB of high-speed SRAM, partitioned to keep data local to the processing tiles, minimizing latency.
Interconnects: Eschewing the industry-standard InfiniBand, Microsoft has opted for an Ethernet-based fabric, a choice intended to lower costs and simplify datacenter integration while maintaining the high-intensity data movement required for large-scale inference.
Shifting the Economic Needle
The headline figure for Azure customers and investors isn’t just raw speed, but “performance per dollar.” Microsoft claims the Maia 200 offers a 30% improvement in cost-efficiency compared to the existing hardware in its fleet.
“Maia 200 is an AI inference powerhouse,” stated Scott Guthrie, Executive Vice President of Cloud + AI at Microsoft. By optimizing the chip specifically for the “reasoning” phase of AI—generating tokens rather than training models—Microsoft is targeting the highest-volume portion of the AI lifecycle.
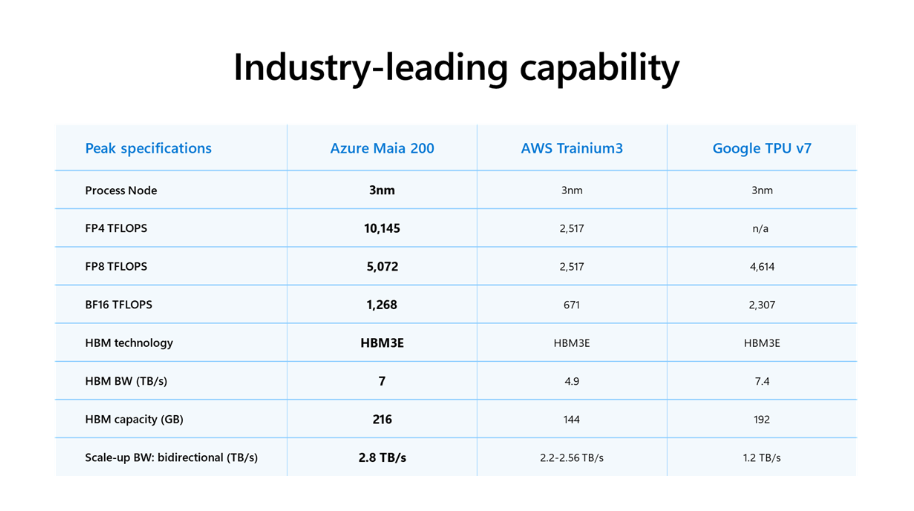
Competitive Landscape: The “Hyperscaler War”
Microsoft’s launch note contained a direct “message” to its primary cloud rivals, Amazon and Google. The company explicitly claims the Maia 200 is:
3x faster in FP4 performance than Amazon’s latest Trainium 3.
More performant in FP8 workloads than Google’s TPU v7.
While Microsoft maintains a close partnership with NVIDIA, utilizing their H100 and Blackwell GPUs for heavy-duty training workloads, the Maia 200 represents a clear effort to reduce reliance on third-party silicon for everyday inference tasks like Microsoft 365 Copilot and Bing Search.
Deployment and the “Superintelligence” Team
The rollout of the Maia 200 is already underway, with the chips live in Microsoft’s Iowa (US Central) datacenters. Expansion to Arizona (US West 3) is slated for the coming months, with a global rollout continuing throughout 2026.
One of the first major internal users is Microsoft’s Superintelligence team, led by Microsoft AI CEO Mustafa Suleyman. The team is reportedly utilizing the silicon for synthetic data generation and reinforcement learning—critical components in the development of “frontier” AI models that require higher-quality data than what is currently available on the open web.
Looking Ahead: The Maia 300
Microsoft is not slowing down; the company confirmed that the successor, the Maia 300, is already in the design phase. As the demand for AI inference scales toward trillions of tokens per day, the success of the Maia series will likely determine Azure’s ability to offer the most competitive pricing in the enterprise AI market.
For developers, a preview of the Maia SDK is now available, featuring PyTorch integration and a Triton compiler, allowing labs and enterprises to begin optimizing their models for this new architectural tier.
Hey, great read as always. Super interesting how Maia 200 really hones in on inference. What if this cost-efficiency means AI becomes so cheap it totaly changes how we think about personalized learning tools? That Ethernet choice for datacenters is smart too. So much potential!