Alibaba’s Qwen 2.5-Max: A Game-Changer or Just Another AI Mirage?
Following in the footsteps of DeepSeek, Chinese tech giant Alibaba has strategically launched its Qwen 2.5-Max AI model on the first day of the Chinese Lunar New Year, underscoring the urgency it feels in the face of fierce local competition.
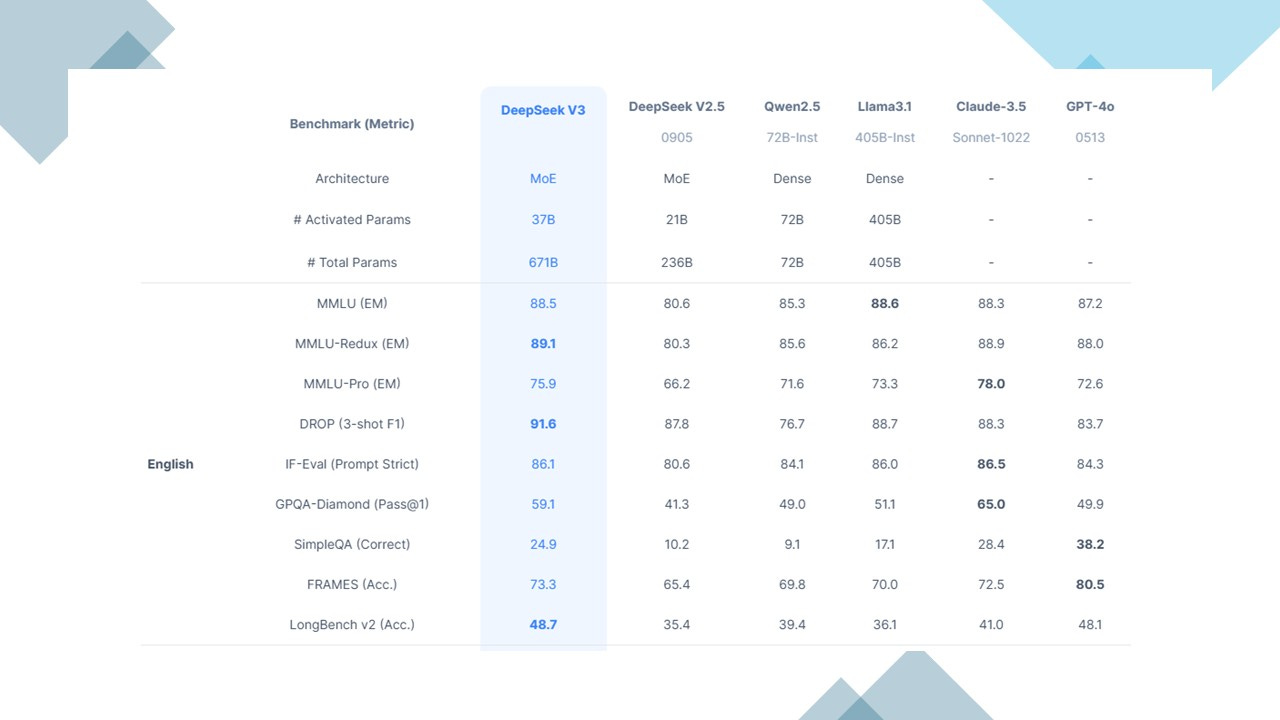
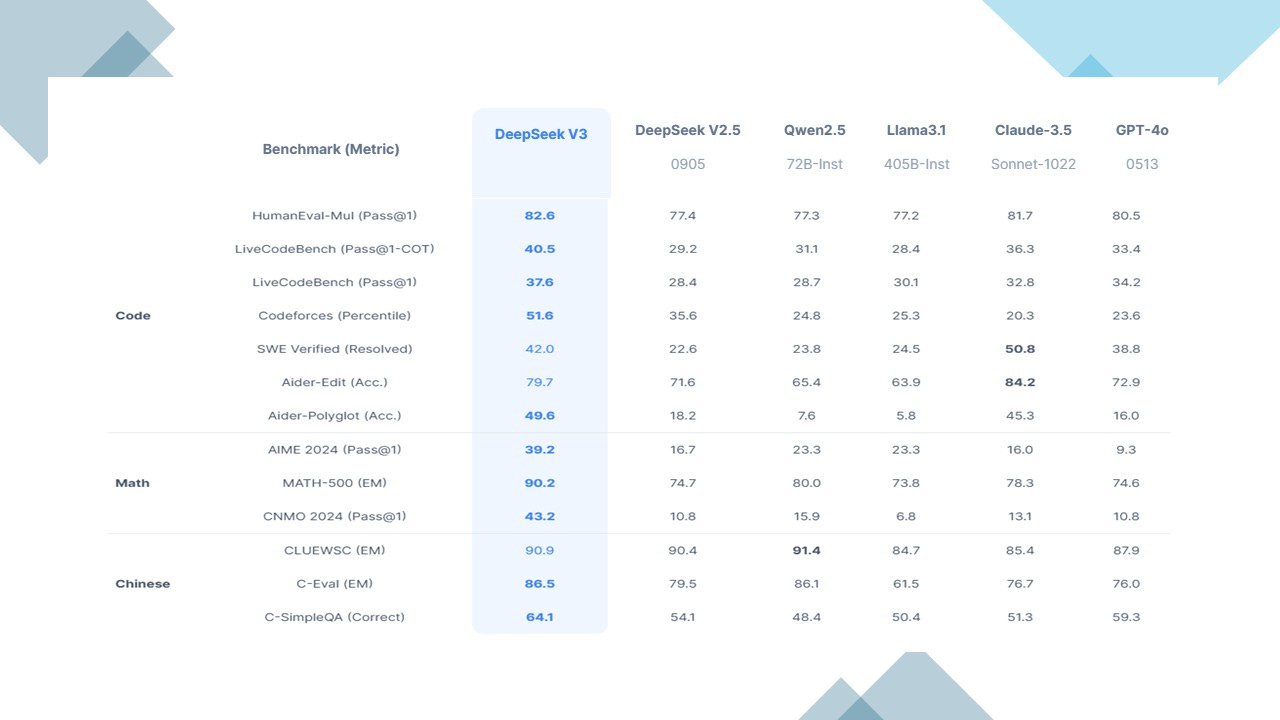
Alibaba claims that Qwen 2.5-Max outperforms DeepSeek-V3 and other leading AI models, including OpenAI’s GPT-4o and Meta’s Llama-3.1-405B. However, growing skepticism over DeepSeek’s claims casts a shadow over Qwen 2.5-Max and other potential Chinese contenders.
Qwen 2.5-Max is the latest advancement in Mixture of Experts (MoE) models by Aliyun’s Tongyi team, trained on over 20 trillion tokens. According to Chinese media, developers can access the model for free via the Qwen Chat platform.
Ironically, OpenAI—the creator of ChatGPT—suspects that DeepSeek’s impressive performance stems from leveraging OpenAI’s proprietary data. The Financial Times reported that OpenAI has evidence linking DeepSeek to model distillation techniques, which may explain how DeepSeek trained its model at a fraction of OpenAI’s cost, requiring fewer than 3,000 H800 GPUs.
Meanwhile, Bloomberg revealed that OpenAI and Microsoft are investigating whether DeepSeek used OpenAI’s API to integrate its AI models into DeepSeek’s own. Given that OpenAI is a closed-source system, this raises a crucial question: How did DeepSeek obtain access to its data?
DeepSeek must address these allegations, or risk casting doubt on the credibility of other Chinese AI models claiming superior performance. Without transparency, skepticism will continue to cloud the achievements of China’s AI industry in the global race for artificial intelligence dominance.
Read or listen to our co-authored analysis with AI Supremacy on DeepSeek: